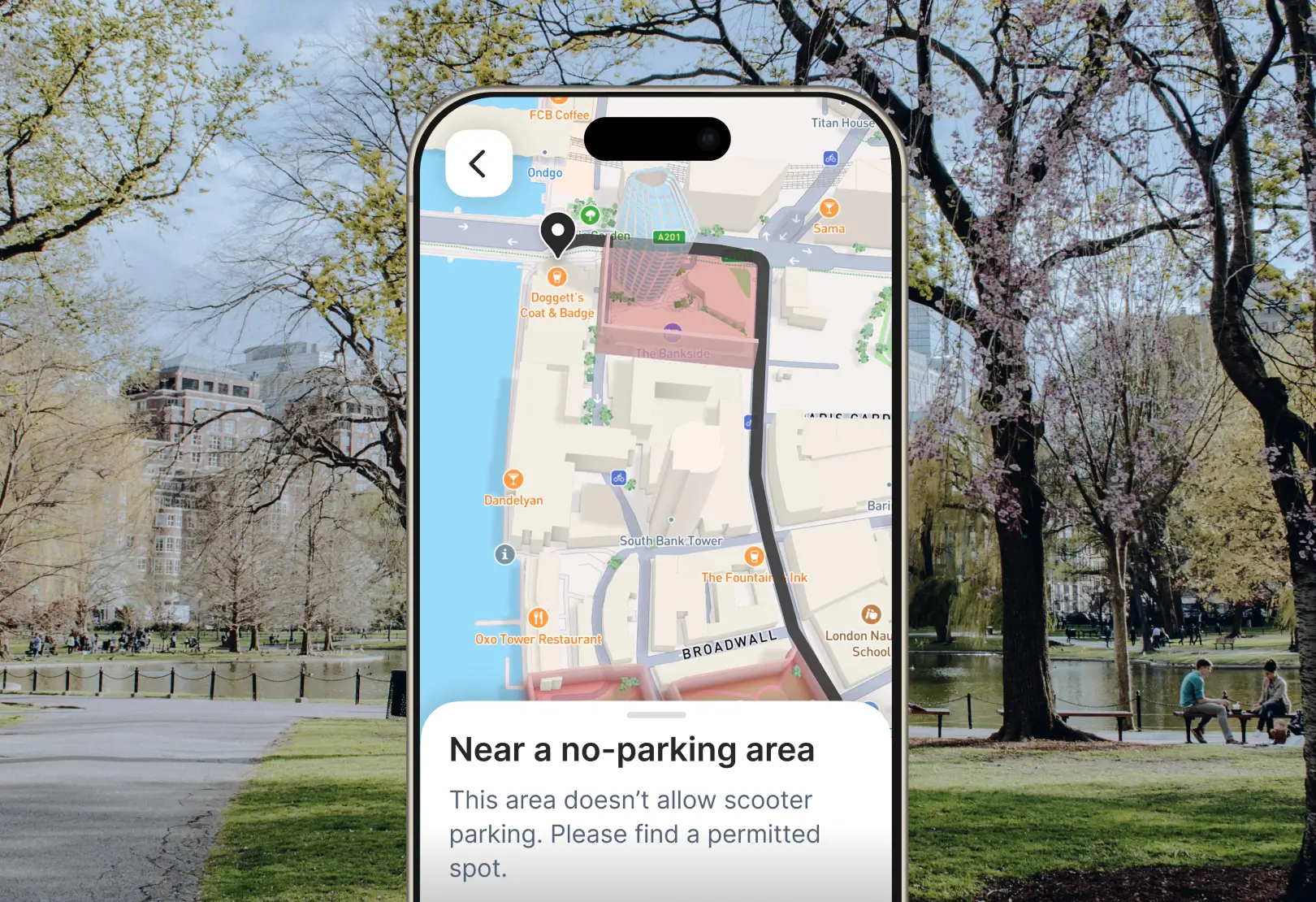
New Geofencing API simplifies managing large-scale geofences
Upload and monitor geofenced areas, then trigger alerts. For example, ODL organizations could issue alerts when an order is near its destination, or help delivery drivers avoid restricted driving zones.
Deliver on time with optimized routes and ETAs
Dispatch orders efficiently, reduce costs, and minimize delays

Dispatch the best driver for every delivery
The Mapbox Matrix API identifies the most efficient route and driver for any delivery by comparing travel times between several locations.
Mapbox Matrix API →
Plan routes for efficiency
The Mapbox Optimization API can identify the ideal route and sequence for any set of deliveries. Accommodate the need for multiple pickup and dropoff locations, urgent deliveries, variable time windows, or specific vehicle requirements.
Mapbox Optimization API →


Navigate to optimal arrival points
Mapbox Geocoding excels in handling complex pickup and dropoff scenarios. With rooftop accuracy, unit-level addresses, and road network awareness, Mapbox provides practical routes to guide couriers to the best entrance or parking spot.
Mapbox Geocoding →
Add highly-accurate, traffic-aware ETAs
Calculate accurate estimated pick-up and drop-off times based on live or future traffic conditions, without the need to purchase and integrate third-party traffic data.
Mapbox Matrix API →

Maximize reach with smart distribution networks
Locate hubs to serve more customers and speed up delivery

Visualize coverage and gaps
Pinpoint ideal sites for stores, distribution centers, dark stores, restaurants, and more. Measure a pickup and delivery radius for every vendor or competitor. Understand the geography of demand and the travel times required to meet it.
Mapbox Isochrones API →
Plan expansion based on where customers are
Track signals on how people, packages, and vehicles are moving. Combine proprietary data with location intelligence to identify the next demand hotspot.
Mapbox Movement Data →
Delight customers and couriers
Keep customers informed about delivery status and make deliveries on time

Keep your customers in the loop
Provide location transparency throughout the delivery lifecycle. Visualize order tracking data to provide delivery progress updates in-app.
Mapbox Mobile Maps SDK →
Add navigation into custom applications
Keep couriers on route with navigation features directly embedded within their driver app. Provide turn-by-turn directions and correct deviations in real-time. Add EV features to account for vehicle battery and charging.
Mapbox Navigation SDK →

Customer stories
.jpg)
Mapbox provides DoorDash with accurate estimated arrival times, optimized delivery routes, and enhanced visual maps, all deployed at scale for millions of deliveries.

Instacart uses Mapbox geocoding and logistics services to enhance their app experience with real-time tracking, precise geocoding, and intelligent route optimization.
Read showcase →

With the Mapbox Navigation SDK, Picnic added in-app routing and turn-by-turn directions so that drivers can use the Picnic driver app to optimize deliveries.
Read showcase →

The Mapbox Matrix API and real-time traffic data improve the accuracy of Wolt's delivery estimates, benefiting drivers, vendors, and customers.
Read showcase →
Resources

The Future of On-Demand Logistics: Trends and Solutions from Mapbox

How Mapbox Helps On-Demand Logistics Leaders Scale

How Mapbox Drives Efficiency and Business Growth in On-Demand Logistics
Ready to get started?
Create an account or talk to one of our experts.